by batman Fri Aug 02, 2019 11:46 pm
by batman Fri Aug 02, 2019 11:46 pm
Hi There,
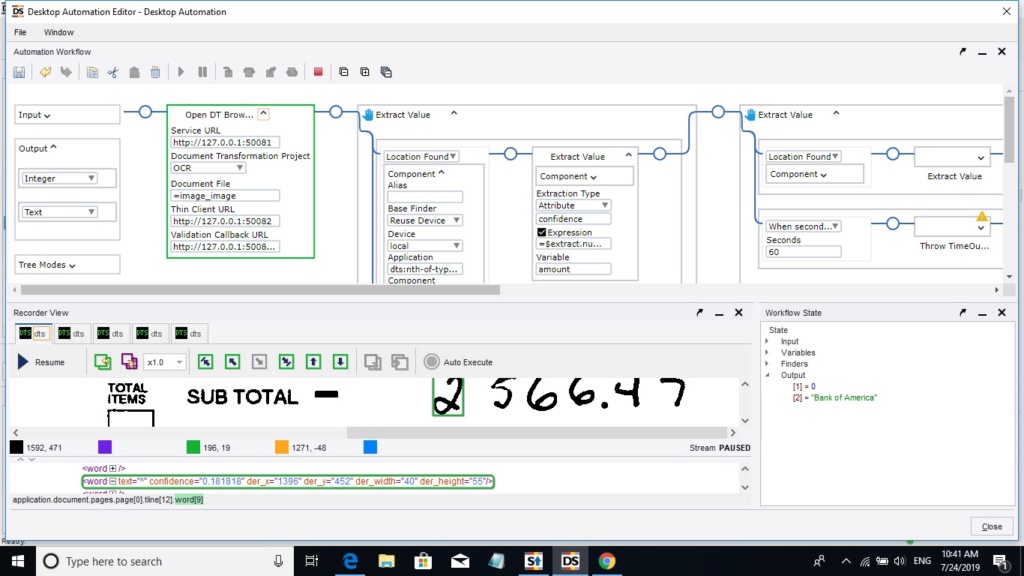
Transformation Project Builder is the right place to be defining your classification and extraction setup, Design Studio itself has some basic OCR capability but it's very limited compared to Transformation. Transformation itself is incredibly powerful for document processing and provides much more than just OCR (and also means there's a bit of learning curve to get up to speed)
I would start by splitting your task into 2 parts to start with
1. Define the extraction config in Transformation Designer
2. Call your transformation project from within your RPA process and map the results across to your process variables
For part 1 here's are the high level steps required..
- Create a new project in Project Builder
- Load your test image(s) by selecting the Open Document Set button in the Document window. Select the path to your file(s) and click ok.
- Add a class for the document you are processing (Right click the Project Class at the root of the project tree and select add Class)
- For now just set that as the default document type (Right click the new class and select Default Classification Result). This will route any submitted documents to that class, so if you start introducing new document types and formats this will need extending with training data to distinguish between the different types.
- Add a locator to extract the data you need. Expand the new class, right click locators and select Add Locator.
- Configure the locator. In the centre of the screen you will see a drop down for locator methods (with lots of possibilities!). This is where the learning curve starts as there so many approaches that can be used to improve the accuracy of extracted data. For your use case I would recommend the advanced zone locator
- Configure the locator by clicking the button to the right on the locator drop down.
- For an Advanced Zone locator start by adding a reference image. Provided you have sample images loaded you should be able to just click the Insert Sample button
- Ignore Anchor and registration for now (these help when you have skew and content that moves around each time)
- Goto the Zones tab and click the Add button, this will create a new field for you in the locator
- Double click the new zone to configure it.. this is where you can then start defining the region on the image, perform image cleanup etc. and test your results.
- Recognition profiles are selected in the bottom right of the zone configuration, some are dedicated to hand print others machine and some mixed (Finereader does well for words and machine print but not so well for mixed character sets and handwriting, Recostar works well for mixed character sets, handwriting and also allows you to force regular expressions during recognition)
- Test the results using the Test button. When happy close the Zone locator config window
- Create a field by right clicking the project tree and selecting Add Field
- Give the field a name and in the configuration assign the result of the locator to this field
- Save your project and smile
For Part 2
- See the examples provided for Invoices/Full Text OCR to see how projects are referenced and fields are mapped back to your robot.
As Ivan suggested you also need to think carefully about introducing OCR into automated robotic use cases. OCR itself will never be 100% accurate especially on handwritten content so there's a very high chance that users will need to get involved in the process and manually correct/validate the results. Kofax RPA includes a browser based validation interface to support this but it's something to bear in mind if you are expecting the correct results to be returned each time.
This is then your next step, adding a call back robot that receives the validated results and delivers the data where you need it to go but probably best starting with the first step and seeing how you get on ;-)
Once you get the hang of it it's a lot simpler than it sounds and most use cases are pretty quick to deploy.
Let me know how you get on and happy to help you along the way where I can.