Hi,
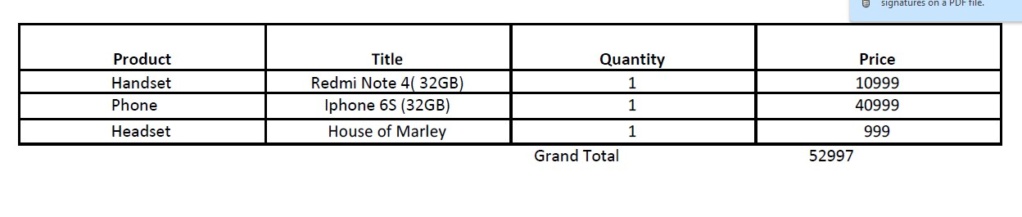
PDF has Tables inserted with it. when PDF is loaded into Kapow, tables are not aligned and i am not able to loop through these tables.
Table contains Product, Title, Quantity and Price fields
I have used "Loop for Each Tag" so as to loop through these fields and fetch the next Line item.
But, Kapow is not able to identify the next line item.
Can somebody help me resolve this issue?
Thanks
Tejaswini H R

PDF has Tables inserted with it. when PDF is loaded into Kapow, tables are not aligned and i am not able to loop through these tables.
Table contains Product, Title, Quantity and Price fields
I have used "Loop for Each Tag" so as to loop through these fields and fetch the next Line item.
But, Kapow is not able to identify the next line item.
Can somebody help me resolve this issue?
Thanks
Tejaswini H R