


็็Hi i use 'Design studio 10.4.0.0'
I have the problem about try to extract data from pdf file. The table in pdf is show as image and information is my local language (thai language). I saw it can extract correct only number and english words.

In image i point at thai word is the name of company "บริษัท" but it show attribute in word text=1Jtgvt
Do you know how i can extract local language as the correct word?
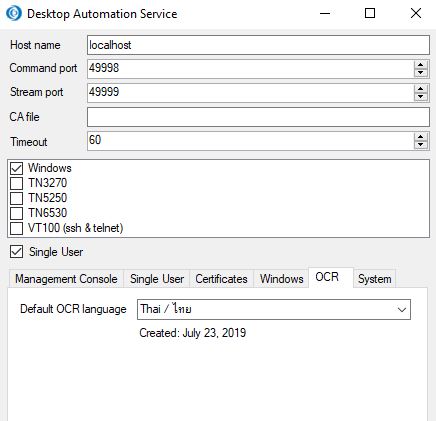
I am also setting my language here but it not help OCR in 'Design studio' to understand it
And if it not has the solution to extract data from local language in OCR. Any advice to enter text at the image directly to be final value i want?
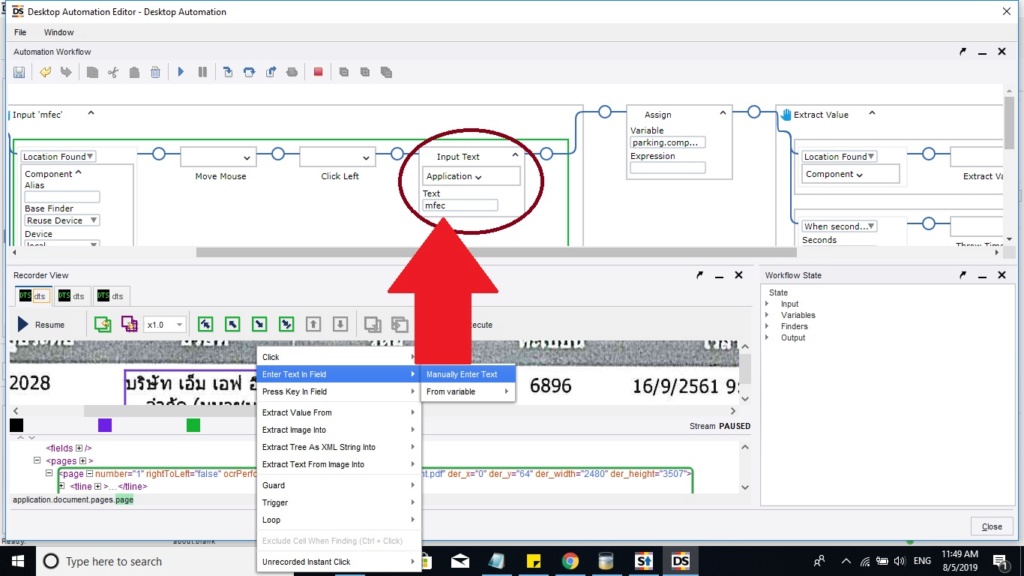
In the picture as long as i try about my local language in OCR and it can't do.So, i try use "Manually ebter text in field" and then assign step to variable
"parking.company" when parking is output type.
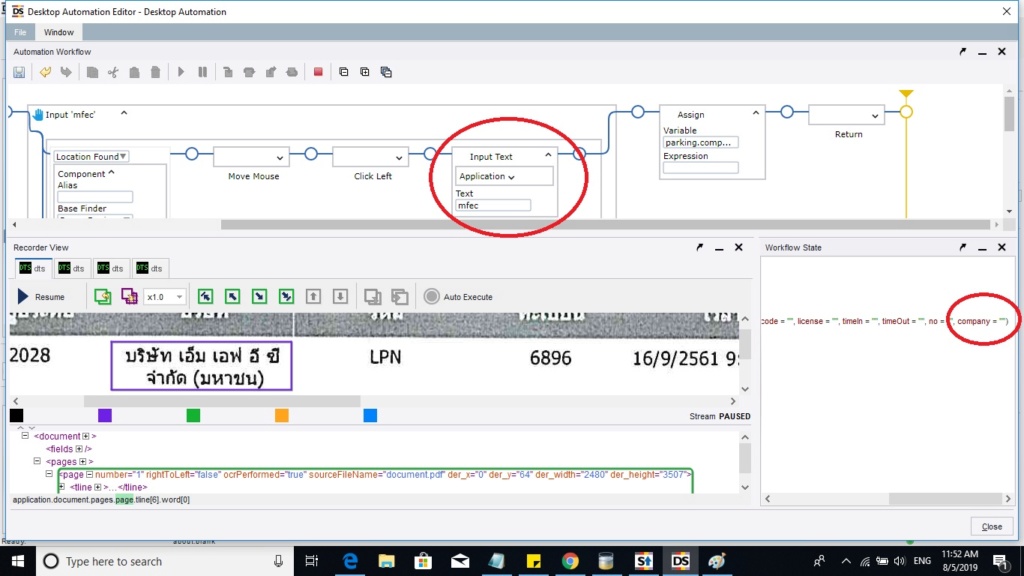
I expected it will have word "MFEC" when OCR found that image area but finally variable name company still be empty string "" in picture
Can anyone suggest me how i can put input to my variable on that area image OCR can't extract data correct? Thank you
I have the problem about try to extract data from pdf file. The table in pdf is show as image and information is my local language (thai language). I saw it can extract correct only number and english words.
In image i point at thai word is the name of company "บริษัท" but it show attribute in word text=1Jtgvt
Do you know how i can extract local language as the correct word?
I am also setting my language here but it not help OCR in 'Design studio' to understand it
And if it not has the solution to extract data from local language in OCR. Any advice to enter text at the image directly to be final value i want?
In the picture as long as i try about my local language in OCR and it can't do.So, i try use "Manually ebter text in field" and then assign step to variable
"parking.company" when parking is output type.
I expected it will have word "MFEC" when OCR found that image area but finally variable name company still be empty string "" in picture
Can anyone suggest me how i can put input to my variable on that area image OCR can't extract data correct? Thank you
Last edited by DeepMind123 on Mon Aug 05, 2019 12:04 pm; edited 1 time in total (Reason for editing : no one answer me, I try other solution but still stuck in problem.So, i put my new solution to let other people know)

